沐神的课
BERT
名字来源
Bidirectional Encoder Representations from Transformers
模型架构
In this work, we denote the number of layers (i.e., Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A.
We primarily report results on two model sizes:
BERTBASE (L=12, H=768, A=12, Total Parameters=110M ) and
BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)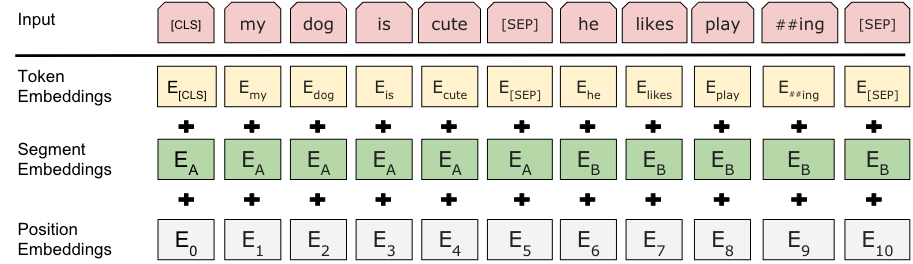
每一个输入的词元变成三个标注:
1.token;词本身的信息
2.segment;代表是哪个句子
3.position;位置信息
超参数-》可学习参数的大小(回顾Transformer)
可学习参数主要来自两块:
1.嵌入层;
2.Transformer块;
模型使用的分词
wordPiece
根据词出现的频率来做分词
Transformer
模型架构
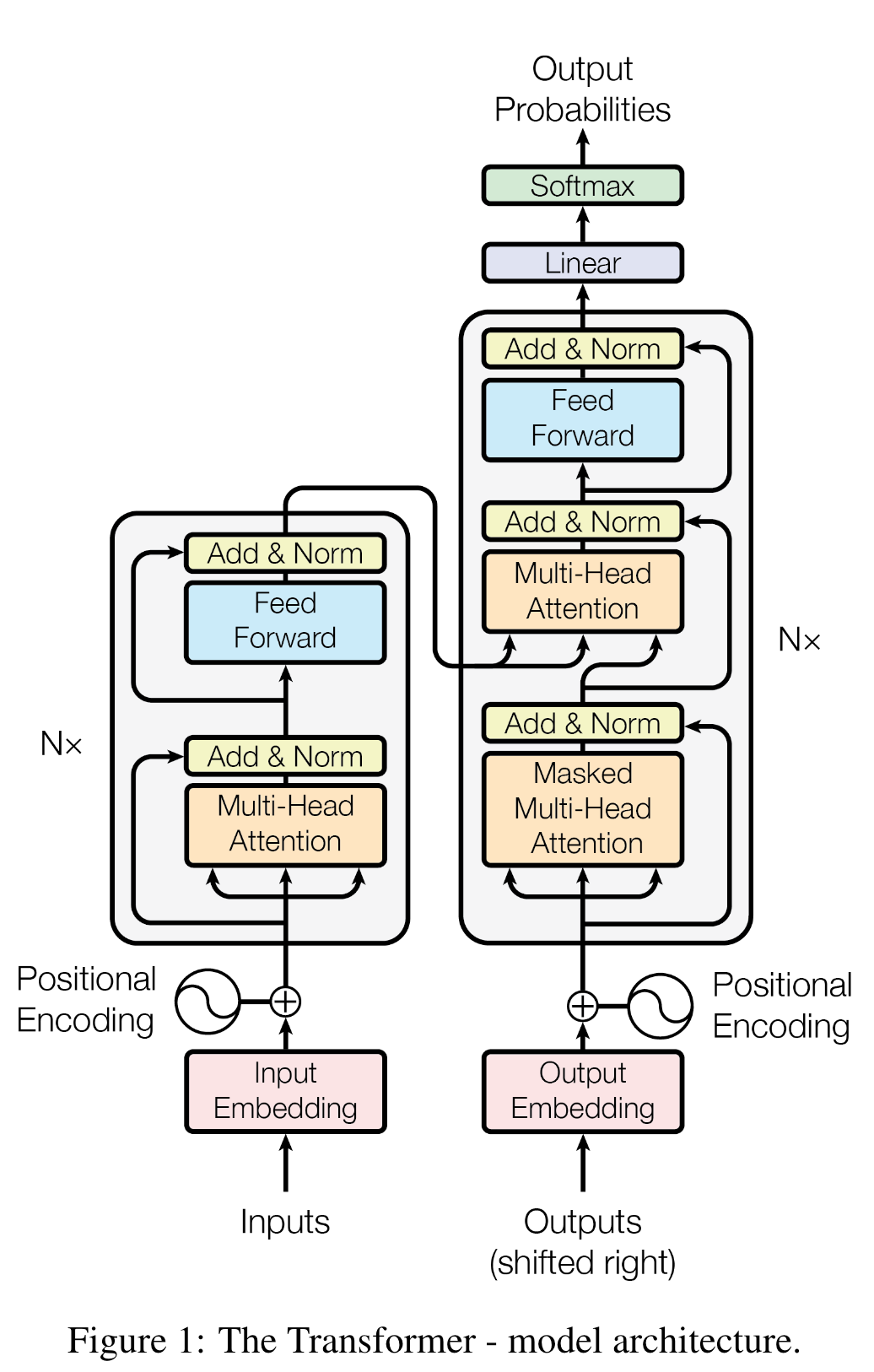
具体解释
Encoder
可以看到从输入进来之后,输入变成了三份(key, value, query),实际上就是输入本身复制了三份,因此,这种注意力机制也可以被称作为自注意力机制;
然后之所以使用多头注意力机制,是因为单个头注意力机制中需要学习的参数太少,而在多头注意力机制中,引入了W参数作为可学习参数,类似于卷积神经网络中的多通道。
Decoder
编码器端的key和value是来自于编码器的最后一层的输出,而query是来自于解码器经过多头注意力机制的输出,这一部分的含义是指寻找解码器的query于key相似的作为下一层的输入。
scaled dot-product attention & multi-head attention
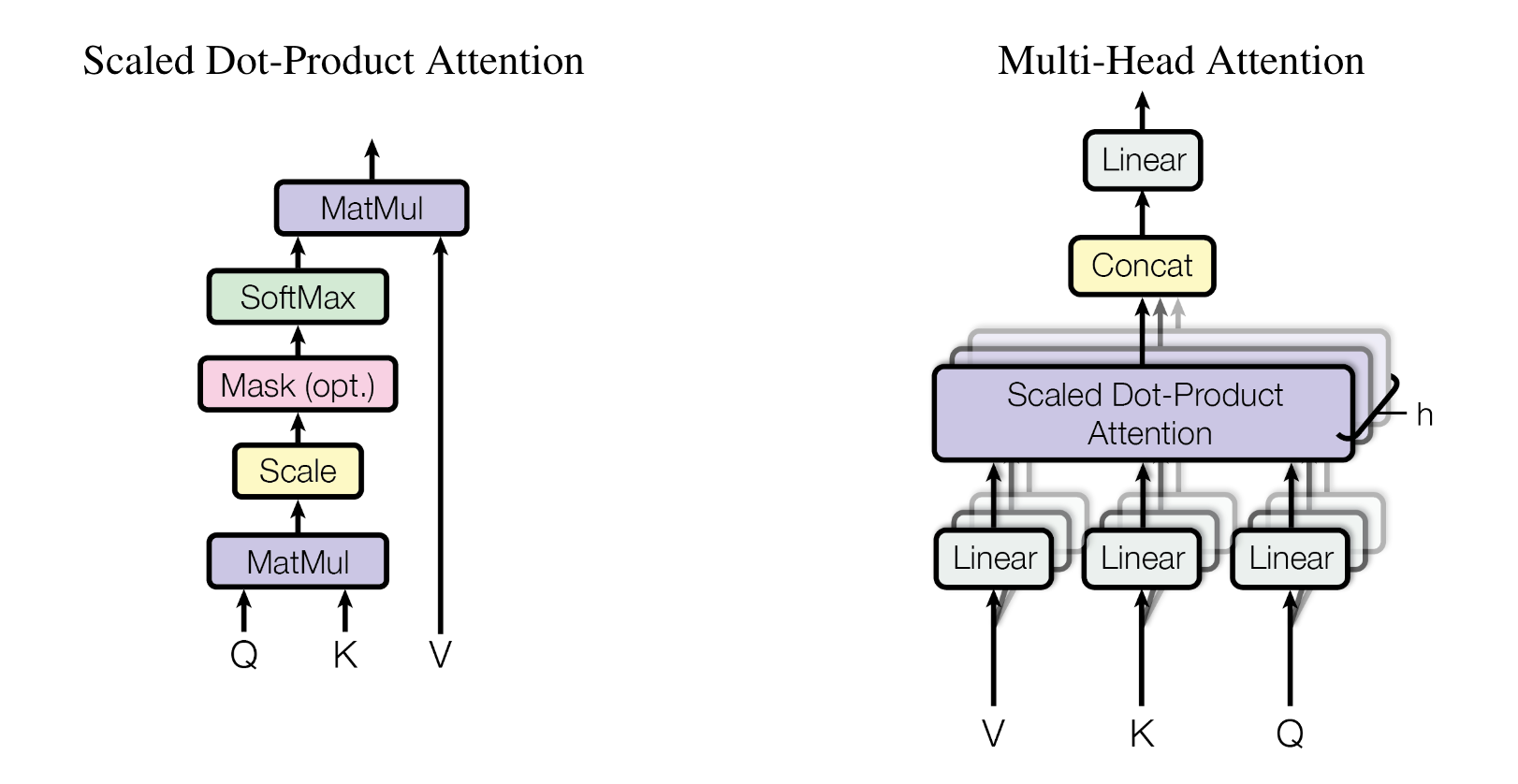
可以看到头的个数为h。把输入映射到低维空间(d-model / h)中,然后最后进行拼接成原始的维度(d-model)
dropout 层
drop = 0.1?正则化?